![]()
변수는 함수 외부에 선언될 수 있다. 이러한 변수를 전역 변수(global variables)라 부른다. 예를 들면, 다음 코드에서

g는 전역변수이다. 여러분은 fun() 내부에 선언된 n은 지역변수임을 알고 있다.
전역 변수는 지역 변수와는 달리, 이 변수가 선언된 이 후에 정의되는 모든 함수에서 별도의 선언 없이 사용될 수 있다. 따라서 전역 변수가 프로그램의 첫 부분에 선언된 경우에는, 프로그램 전체에 걸쳐서 사용 가능하다.
변수가 사용될 수 있는 프로그램의 영역을 변수의 영역(scope)이라 부른다. 따라서 지역 변수의 영역은 이 변수가 선언된 함수 내부가 되며, 전역 변수의 영역은 이 변수가 선언된 이후의 프로그램의 모든 영역에 해당된다.
앞서, 지역 변수는 함수의 호출시에 생성되며, 함수의 실행이 종료되면 사라진다고 설명하였다. 반면에, 전역 변수는 선언 이후부터
프로그램 종료시까지 존재한다. 즉, 전역 변수는 일단 생성되면, 프로그램과 함께 그 수명을 같이한다고 볼 수 있다.
 |
프로그램의 첫 부분에 선언된 변수 a는 함수 외부에서 선언되었기 때문에 전역 변수이다. main()과 fun()은 각각 자신의 지역 변수 b가 선언되어 있다. 두 함수의 지역 변수가 이름이 같지만, 그 영역이 함수 내부에 제한되기 때문에 문제가 되지 않는다.
또한, fun()에서 a를 참조하고 있다. a가 fun()에서 선언되어 있지 않기 때문에 오류가 발생하는가? 그렇지 않다. a는 전역 변수이고, 따라서 그 영역은 프로그램 전체이고, 프로그램에 포함된 어떤 함수에서도 올바르게 참조 가능하다.
프로그램 15-2 실행 과정을 전역변수와 지역 변수간의 차이를 살펴보자. 프로그램 실행은 다음과 같이 4단계로 구분된다.
 |
|||
main()에서
처음 두 번째 문장 scanf()까지 실행되었을 때를 생각해보자. 사용자가 다음과 같이 입력하였다고 가정한다.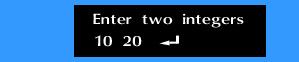 다음은 함수 프레임을 보여준다. main()의 지역 변수 b는 main 프레임에 포함되나, 전역 변수 a는 함수 프레임에 포함되지 않고, 그 외부에 위치하는 것을 볼 수 있다. 이것은 전역변수가 특정 함수에 연관되지 않는다는 것을 보여주기 위함이다. 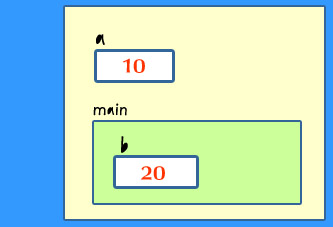 |
|||
 |
|||
|
다음은 main()에서
fun()이 호출되었을 때의 함수 프레임을 보여준다. fun()의 지역 변수 b가 fun 프레임에 생성된다. 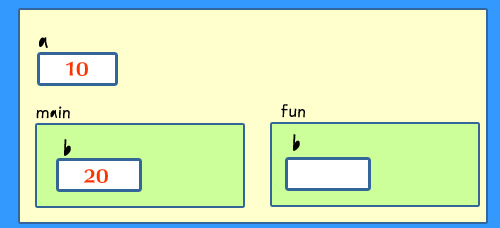 이름이 같은 지역 변수가 b가 각각 main 프레임과 fun 프레임에 존재하는 데, 지역변수의 영역이 함수 내부에 국한되기 때문에 아무런 혼동을 초래하지 않는다. 즉, main 프레임에 속한 b는 그 영역이 main() 내부에 국한되며, fun 프레임에 속한 b는 그 영역이 fun() 내부에 국한된다. fun()의 첫 번째 문장은 a를 참조한다. a가 fun()에 선언되지 않았지만, 오류가 발생되지 않는다. a는 전역 변수이기 때문이다. 프로그램에 포함된 모든 함수는 앞서 선언된 전역 변수를 참조할 수 있다는 것을 기억하라. |
|||
 |
|||
|
다음은 fun()에서
처음 두 개의 배정문을 실행한 후에, 함수 프레임을 보여준다. a의 전역변수는 100으로 변경되고, fun()에 속한
b의 지역변수는 200으로 초기화되는 것을 알 수 있다. 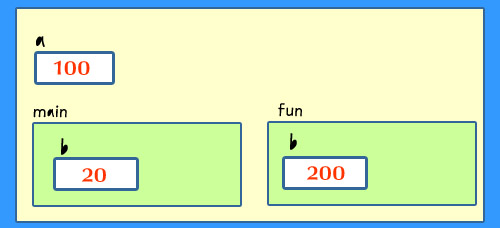 |
|||
 |
|||
|
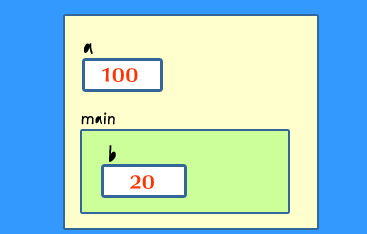
다음은 fun()의 실행이 종료된 직후의 함수 프레임을 보여준다.
fun()의 실행 종료로, fun 프레임은 사라지고, 단지 main 프레임만이 남는다. fun()이 호출되기 직전과
비교하면, a의 전역변수가 10에서 100으로 변경되었음을 알 수 있다.
|
|||